Pythonをとりまく並行/非同期の話
tell-k
Pycon JP 2017


Beproud.inc - connpass

PyQ - Pythonオンライン学習サービス

PyQ - 機械学習はじめました
目的/動機
- 並行/並列処理とか非同期処理ってなんかいろいろ選択肢がよくある
- 普段、断片的に使ったり見たりしてもすぐに忘却してしまう
- 基本的なトピックとかライブラリとか押さえておきたい
- Output を Follow しようと思いました
- Output を Follow しようと思いました
対象
- Pythonは一通り書けるけど、並行/並列処理とかはあまりよく分からない
- 「やだ!あたしのPython時間かかる!」とお嘆きの方
目標

前提
- サンプルコードは Python3.6 です
- 分散システムとかジョブキューとかそういう話はしません
- ライブラリのがっつりした使い方も説明しません
目次
- 並行/並列処理
- 並行/並列処理とは?
- 負荷の種類
- マルチスレッド/マルチプロセス
- 非同期I/O
- コルーチン/イベントループ/I/O多重化
- Pythonの非同期ライブラリ
- asyncioの話
- まとめ
並行/並列処理とは?
並行/並列処理とは?
- 並行(
concurrent)と並列(parallel)という似た用語がある 同義として使われることも多い- 一体どう違うんでしょうか?
並行/並列処理とは?
- ここでは 並列コンピューティング技法 より定義を拝借
- システムが複数の動作を
実行状態に保てることを並行(concurrent)と呼ぶ - 複数の動作を
同時に実行できることを並列(parallel)と呼ぶ - 並行 は 並列を
包含する概念である
雑に言うと
- 本当に複数の処理を同時に実行するのが ->
並列処理 - 複数処理を効率良く切り替えながらあたかも同時に実行するのが ->
並行処理
負荷の種類
負荷の種類
- そもそもプログラムのボトルネックとなる処理にはどういうものがあるのか?
- 大別して2種類ある
- 数値計算のようにCPUを使い続けるような処理 …
CPUバウンド- ファイルの読み書き、DBへの接続、ネットワーク通信 …
I/Oバウンド
- どちらの負荷なのかによって並行処理の取るべき手段が変わる
- 次に実際にPythonで並行/並列処理を書いてみましょう
concurrent.futures
concurrent.futures
- Python3.2 から追加された並行/並列処理用のライブラリ
- PEP 3148 – futures - execute computations asynchronously
- 以前からあった threading 、multiprocessing をより使いやすい統一したAPIを提供
- ここで紹介するのは二つ
- マルチスレッドを扱う
ThreadPoolExecuter- マルチプロセスを扱う
ProcessPoolExecuter
ThreadPoolExecuter
- マルチスレッドのタスクの管理と実行をしてくれるライブラリ
- 複数スレッドを生成し並行に処理を実行する
- I/Oバウンドな処理に向いている
例えば
- スレッドを 3つ 用意して
- 巨大なファイルを読み込む タスクを 6つ 並行に走らせる
というの考える
ThreadPoolExecuter - I/Oバウンドの例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from concurrent.futures import ThreadPoolExecutor, as_completed
def busy_io(index):
# 巨大なファイルを読み込む
with open('large{}.txt'.format(index)) as fp:
content = fp.read()
return 'Finish thread{}'.format(index)
if __name__ == '__main__':
futures = []
worker_num = 3 # ワーカースレッド数
task_num = 6 # 実行タスク数
with ThreadPoolExecutor(worker_num) as executer:
for index in range(task_num):
futures.append(executer.submit(busy_io, index))
# 実行が終わったものから結果を表示
for x in as_completed(futures):
print(x.result())
|
ThreadPoolExecuter - I/Oバウンドの例
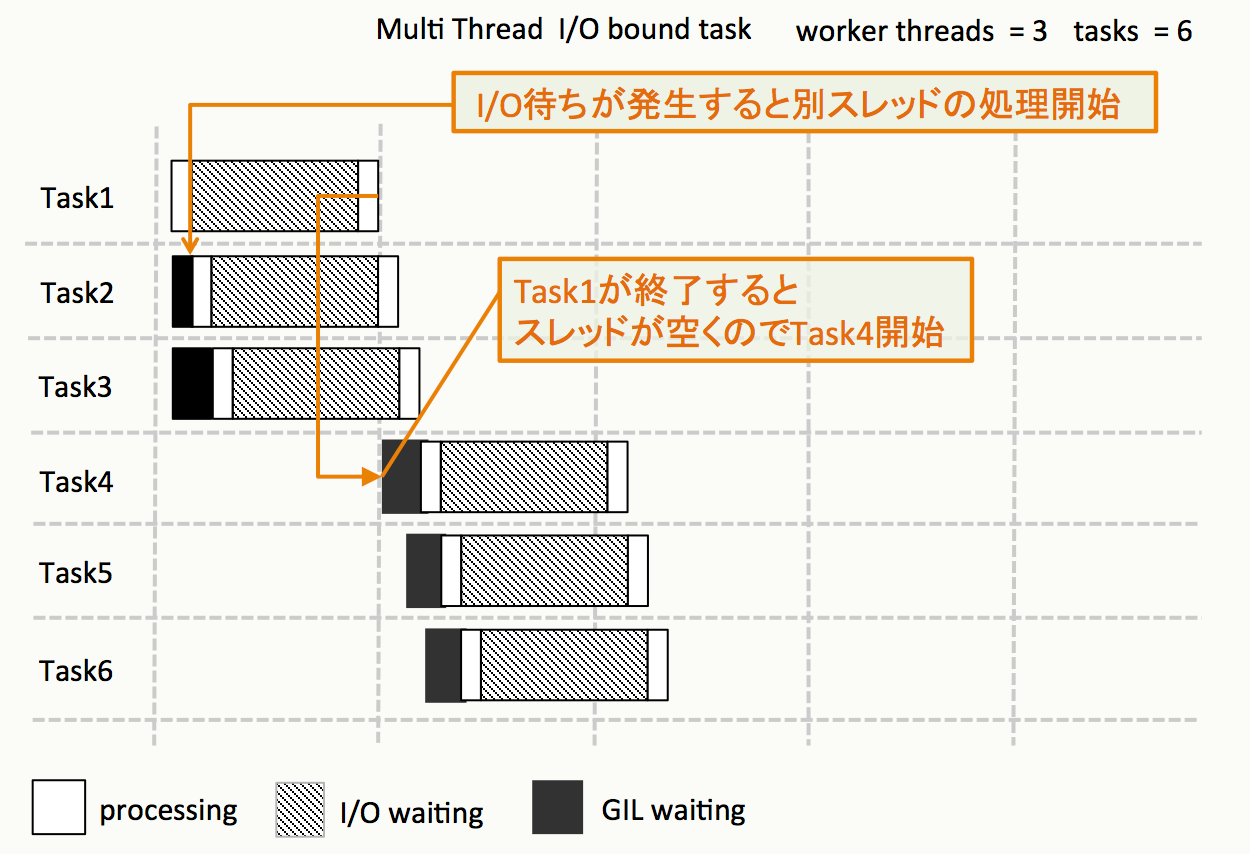
実行するとどうなるか?
- 巨大なファイルを読み込んでる
I/O待ちが発生する - I/O待ちが発生すると、別のスレッドの処理が実行される
- 結果、ほぼ同時に3つのファイル読み込み処理が開始
- ワーカースレッドに空きができたら、未処理のタスクを実行する
- 逐次処理で6回読む込みよりも
処理速度はかなり速くなる
ThreadPoolExecuter - I/Oバウンドの例
ThreadPoolExecuter - CPUバウンドの例
- 次に同じThreadPoolExecuterで
CPUバウンドな処理を実行してみましょう
例えば
- スレッドを 3つ 用意
- 大きな計算をする タスク を 6つ 並行に走らせる
というのを考える
ThreadPoolExecuter - CPUバウンドの例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | from concurrent.futures import ThreadPoolExecutor, as_completed
def busy_cpu(index):
# 大きめの計算処理をする
sum(range(10**8))
return 'Finish thread{}'.format(index)
if __name__ == '__main__':
futures = []
worker_num = 3 # ワーカースレッド数
task_num = 6 # 実行タスク数
with ThreadPoolExecutor(worker_num) as executer:
for index in range(task_num):
futures.append(executer.submit(busy_cpu, index))
# 実行が終わったのものから結果を表示
for x in as_completed(futures):
print(x.result())
|
ThreadPoolExecuter - CPUバウンドの例
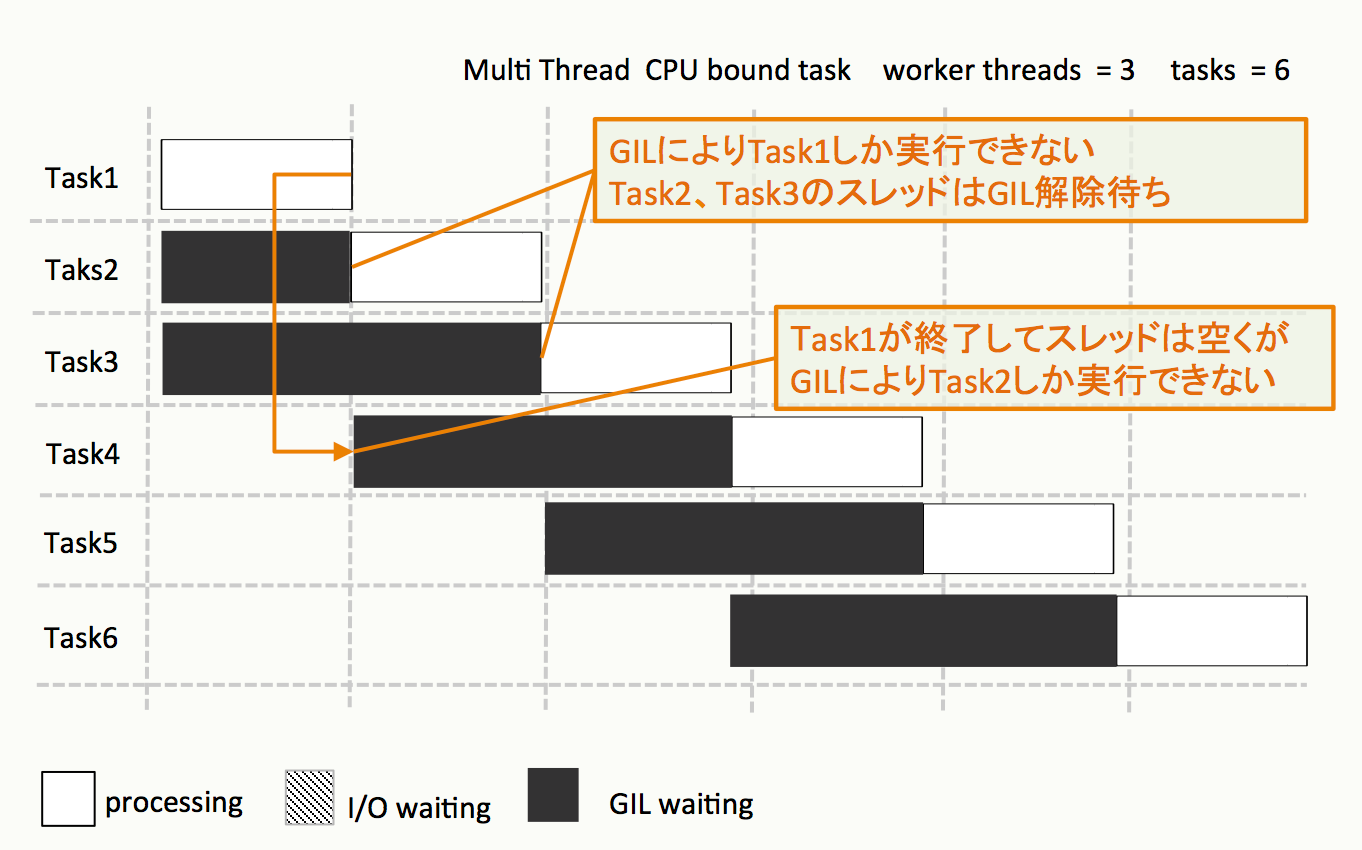
実行するとどうなるか?
- I/Oバウンドな処理と違い、CPUバウンドな処理は逐次的に1タスクづつ実行される
なぜ?
GILという仕組みにより、実行されるスレッドは常に一つに制限されている
結果的に
- 逐次処理で実行するのと、ほぼ
処理時間は変わらない - つまりCPUバウンドな処理をマルチスレッドにしてもあまり嬉しくない
ThreadPoolExecuter - CPUバウンドの例
GILとは?
Global Interpretor Lockの 略称- Pythonのコードを実行できるスレッドは
常に一つのみという制限
なぜ制限あるのか?
- CPythonがスレッドセーフではないCライブラリに依存しているから
- つまりPythonが安全にスレッドを利用するために必要な仕組み
ちなみに
- I/O処理や、一部のC拡張モジュールなどでは
GILが解放されるらしいです - 用語集 > global interpreter lock
- Python3 Advent Calender 3日目 - New GIL を理解する
GIL解放なんてできるの?
- 解放の仕方はドキュメントに書いてある
- 拡張コード内でGILを解放する
注釈
GIL を解放するのはほとんどがシステムのI/O関数を呼び出す時ですが、メモリバッファに対する圧縮や
暗号化のように、Pythonのオブジェクトにアクセスしない長時間かかる計算処理を呼び出すときもGIL
を解放することは有益です。例えば、 zlib や hashlib モジュールは圧縮やハッシュ計算の前にGILを解放します。
- pandas は Cython を 利用して一部の処理をGIL解放している
- Pandas Releasing GIL
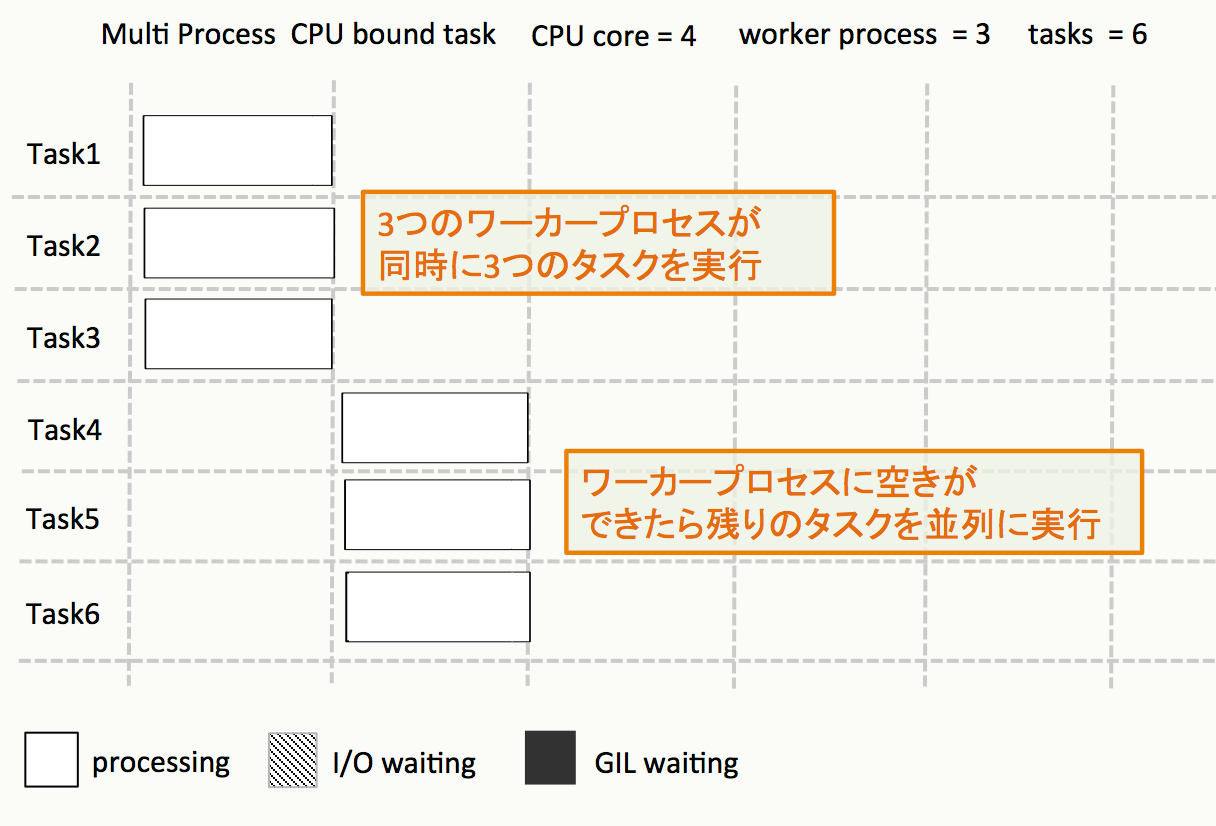
CPUバウンドな処理を並列にするには?
マルチプロセスで並列に実行する- つまり、複数プロセスが独立してタスクを実行するという事
注意点
- 同時に実行できるのは、CPUコア数分のみ
- それ以上はワーカー数(プロセス数)を増やしてもあまり意味はない
1 2 3 | # コア数を確かめる時は?
import os
os.cpu_count()
|
ProcessPoolExecuter - CPUバウンドな例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from concurrent.futures import ProcessPoolExecutor, as_completed
def busy_cpu(index):
# 大きめの計算処理をする
sum(range(10**8))
return 'Finish process{}'.format(index)
if __name__ == '__main__':
futures = []
worker_num = 3 # ワーカープロセス数
task_num = 6 # 実行タスク数
# ProcessPoolExecuterに変えるだけで良い
with ProcesssPoolExecutor(worker_num) as executer:
for index in range(task_num):
futures.append(executer.submit(busy_cpu, index))
# 実行が終わったのから結果を表示
for x in as_completed(futures):
print(x.result())
|
ProcessPoolExecuter - CPUバウンド
ProcessPoolExecuter - CPUバウンド
もしCPUが2コアしかなかったら?
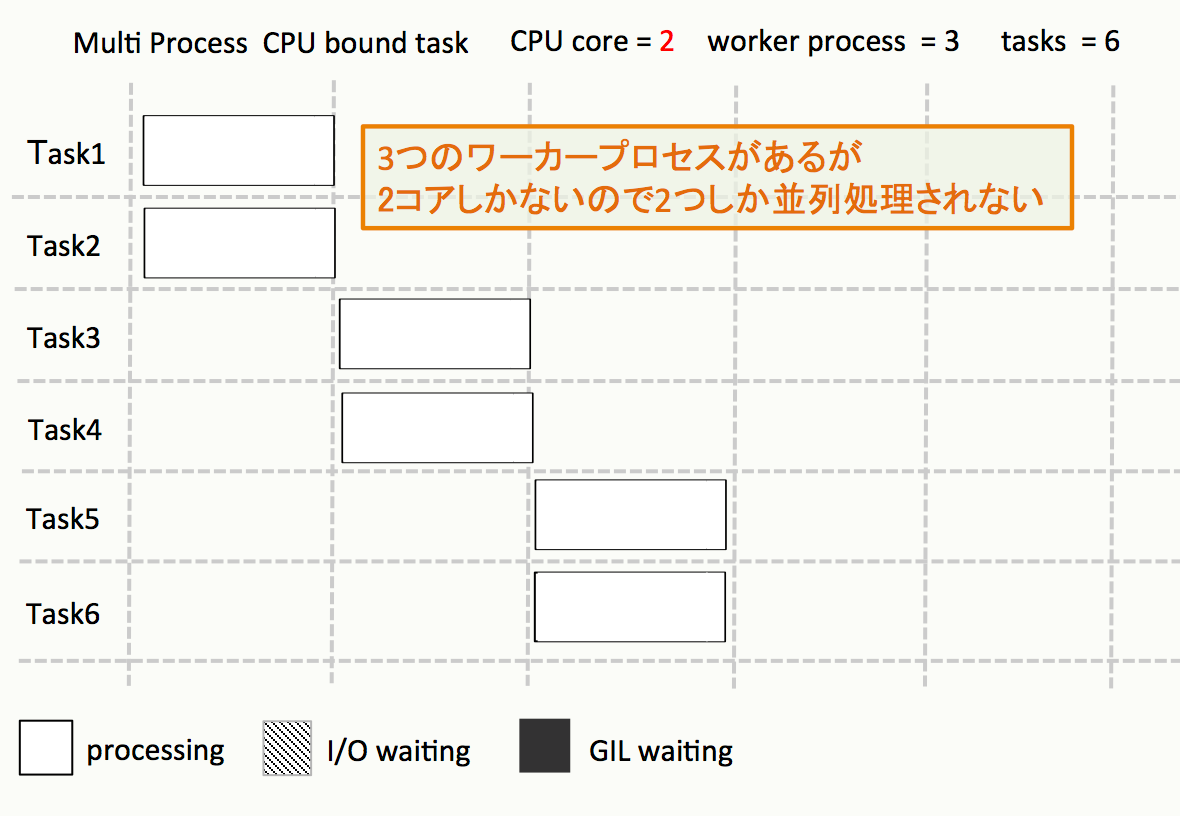
マルチスレッド - メリット・デメリット
- メリット
- I/Oバウンドな処理には効果的
- プロセスに比べて起動コストが低い
- デメリット
- GILがあるためCPUバウンドな処理には不向き
- スレッド間でのデータ競合を気をつけなければいけない
マルプロセス - メリット・デメリット
- メリット
- GILの影響を受けずに並列に処理することができる
- メモリ空間を別プロセスと共有しない
- デメリット
- CPUのコア数を超えて並列化はできない
- スレッドよりもメモリを消費する
- プロセス間通信しないとデータを受け渡せない
シングルスレッドでの処理効率の要求
- かつてWebサーバの C10K問題(クライアント1万台問題) というものがあった
- プロセス数やスレッド数が増えすぎると、メモリを食いつぶしたり、コンテキストスイッチするコストが増大してサーバがパンクしてしまうという問題
- この頃から、シングルスレッドでもより多くの処理を捌くことが要求されるようになった
- その辺から出てきたのが次の
非同期I/Oです
非同期I/O
非同期I/O
- 基本的にI/O処理中はプログラムはブロックされる
- これを
同期I/O(ブロッキングI/O)と呼ぶ - 対してプロックしないようにI/O処理することを
非同期I/O(ノンブロッキングI/O)と呼ぶ
- より正確には
ノンブロッキングI/Oと非同期I/Oは定義が異なる- ノンブロッキングI/Oと非同期I/Oの違いを理解する
- 非同期処理で頻繁に利用される技術を紹介
イベントループI/O多重化コルーチン
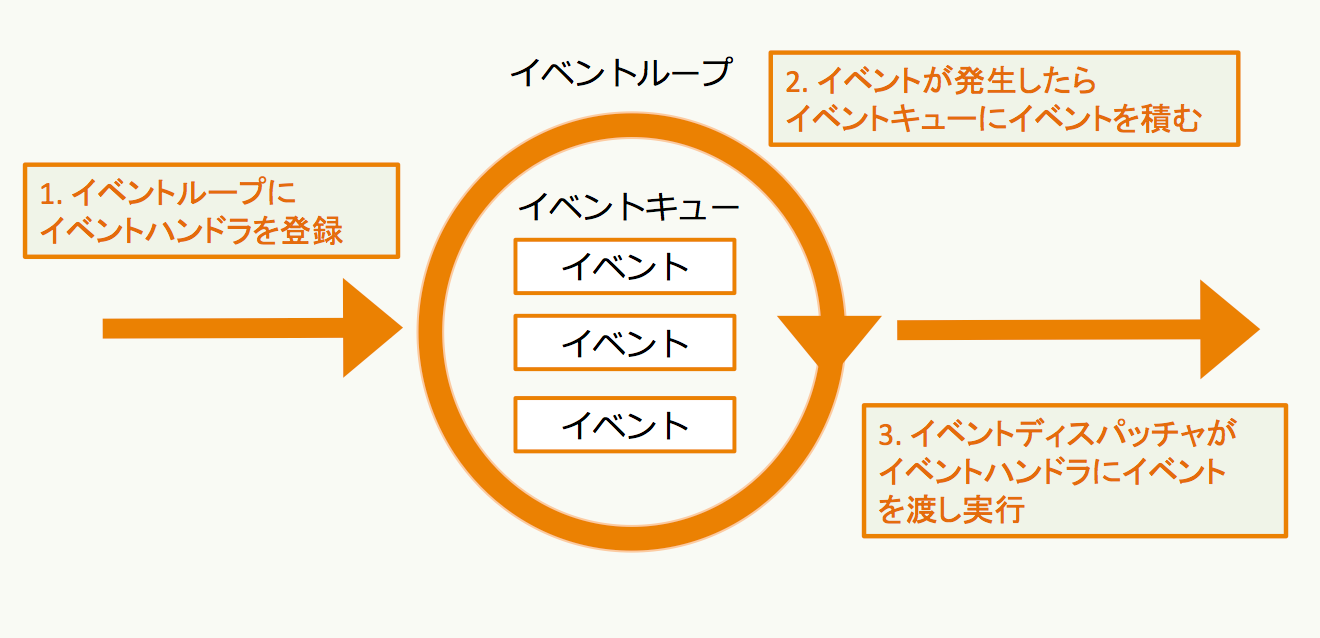
イベントループ
イベント駆動プログラミング- イベントを監視するためのループが
イベントループである
どんな事をするのか?
- 事前にイベントに対応する
イベントハンドラをイベントループに登録 - イベントが発生したら
イベントキューに入れて管理 イベントディスパッチャーがイベントハンドラを実行する
どんなのがイベント?
- ファイルが読み書きできる
- ソケットが読み取り可能になる
- タイマーに設定したタイミング
- シグナルを受け取る
イベントループ
I/O多重化
- シングルスレッドで複数のI/O(ファイル・ディスクリプタ)を扱う必要がある
- UNIX系ではI/O多重化して管理するシステムコール(select/epoll/kqueue)を主に利用
- WindowsではIOCPという同種のAPIを利用する
主にイベントループのライブラリが内部で
- I/O多重化のライブラリを利用して、I/Oのイベントを監視している
- プラットフォームに適したもの自動で利用してくれる
コルーチン
- 処理を任意のタイミングで中断/再開できる機能
- Pythonではジェネレータの拡張構文として実装されている
ジェネレータベースのコルーチン- PEP 342 – Coroutines via Enhanced Generators
ジェネレーターベースのコルーチン
1 2 3 4 5 6 7 8 9 10 | def coro():
world = yield "Hello"
yield world
c = coro()
print(c) # => <generator object coro at 0x10f2df620>
print(next(c)) # => Hello
print(c.send('World')) # => World
|
非同期ライブラリ
- Python には以前から非同期プログラミングをサポートするライブラリが多数あった
- どのライブラリも、先にあげた技術的要素を独自に実装していました
- 結果、同じ非同期処理でも各ライブラリに合わせた実装しなければならなかった
| ライブラリ名 | イベントループ | コルーチン |
| gevent | libev | greentlet |
| Twisted | reactor | inlineCallbacks |
| Tornado | tornado.gen.coroutine | tornado.ioloop |
たくさんフレンズがいるのは良いことだが・・・

asyncio
- Python自身が公式に非同期I/Oのための共通のコンポーネント群を用意
- PEP 3156 – Asynchronous IO Support Rebooted: the “asyncio” Module
- Python3.4 から asyncio モジュールが追加
- Python3.5 から
async/await(ネイティブコルーチン) が利用可能になった
async/await
- Python3.5 からは
asyn/await構文(ネイティブコルーチン) が使える
Python 3.4 以前
@asyncio.coroutine
def hello_world():
print("Hello World!")
yield from asyncio.sleep(1)
Python 3.5 以降
async def hello_world():
print("Hello World!")
await asyncio.sleep(1)
asyncio 挙動の確認
- コルーチンをチェーンする公式のサンプル
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import asyncio
async def compute(x, y):
print("Compute %s + %s ..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()
|

asyncioへの対応(1)
- 基本的にはasyncioを使うように対応する必要がある
- ライブラリは https://github.com/aio-libs にまとまっている
普段に使うようなライブラリの置き換え
- aiohttp(http://aiohttp.readthedocs.io/en/stable/)
- aioredis(http://aioredis.readthedocs.io/en/v0.3.3/)
- aiormysql(https://github.com/aio-libs/aiomysql)
asyncioへの対応(2)
- 既存のライブラリ群も asyncio 対応していっている
非同期系だと
- tornado の tornado.platform.asyncio で asyncioのイベントループが使えたり
- Twisted で async/await が使えたり
asyncioへの対応(3)
- http://uvloop.readthedocs.io/
- libuv + Cython で高速化したイベントループ
- asyncio のイベントループポリシーを差し替えるだけで使える
- コードはそのままにパフォーマンスを向上できる
1 2 3 | import asyncio
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
|
まとめ - 並行/並列処理
- 並行は並列を包含する概念
- マルチスレッドはI/Oバウンドには効果あり
- マルチスレッドはGILがあるのでCPUバウンドには効果なし
- 並列処理をしたいのであればマルチプロセスが良い
- C10K問題くらいからシングルスレッドでも非同期処理が必要になった
まとめ - 非同期I/O
- シングルスレッドで非同期処理
- イベントループ/IO多重化/コルーチンという技術要素で実現
- Pythonの非同期ライブラリ
- asyncioの誕生の背景と概要
- 今後は各種ライブラリがもっとasyncioに対応していくでしょう
感謝
忙しい中、レビューしてくださった。@shimizukawaさん、@crochacoさん、@mahataさん、@kamekoさん ありがとうございました。
また参考にさせていただいた資料、本の著者の皆さま。本当ににありがとうございました。